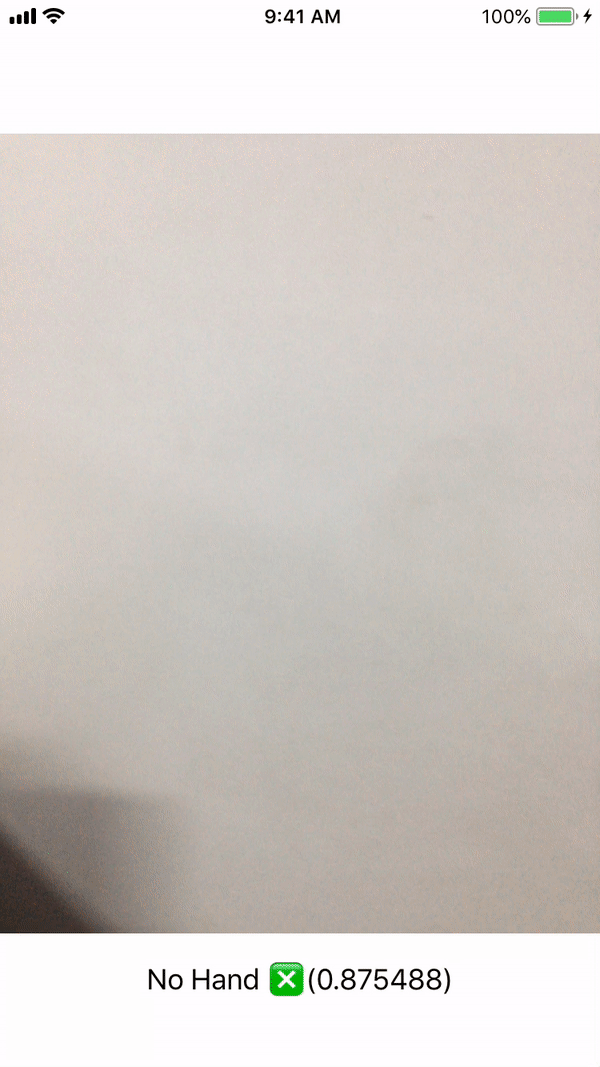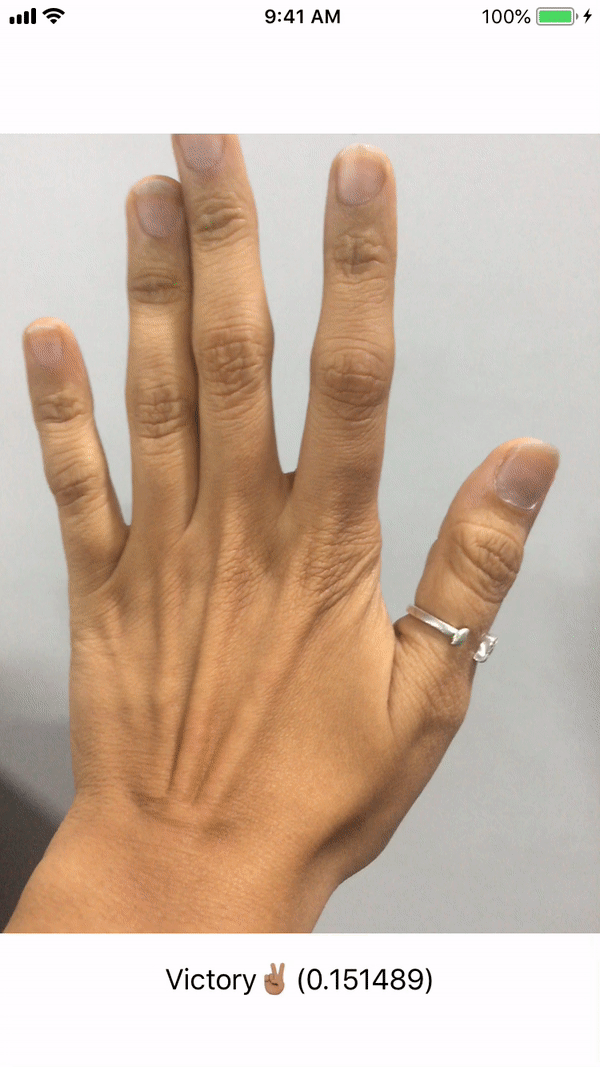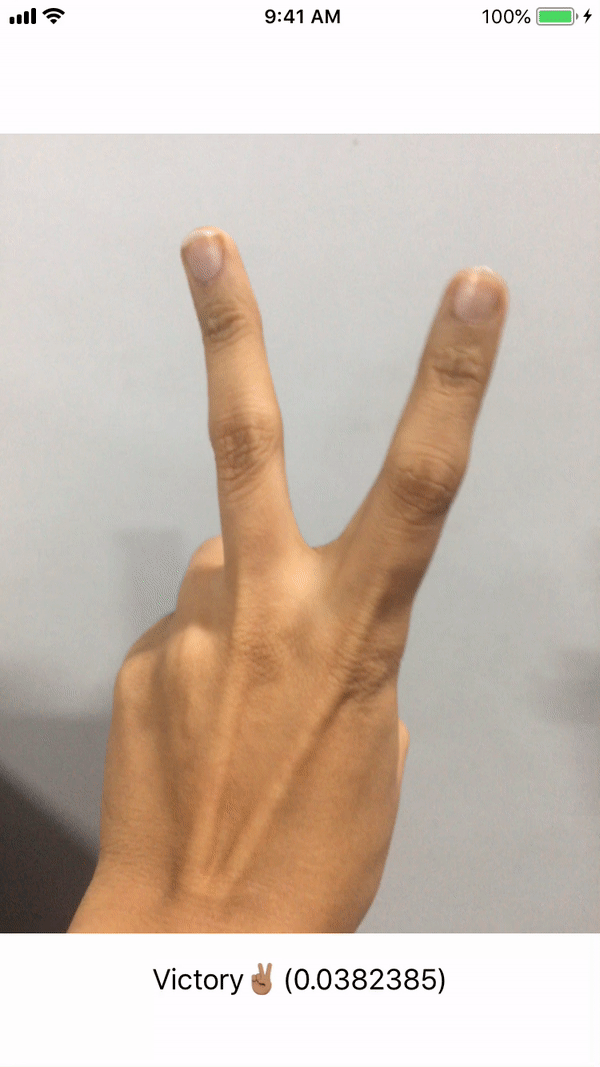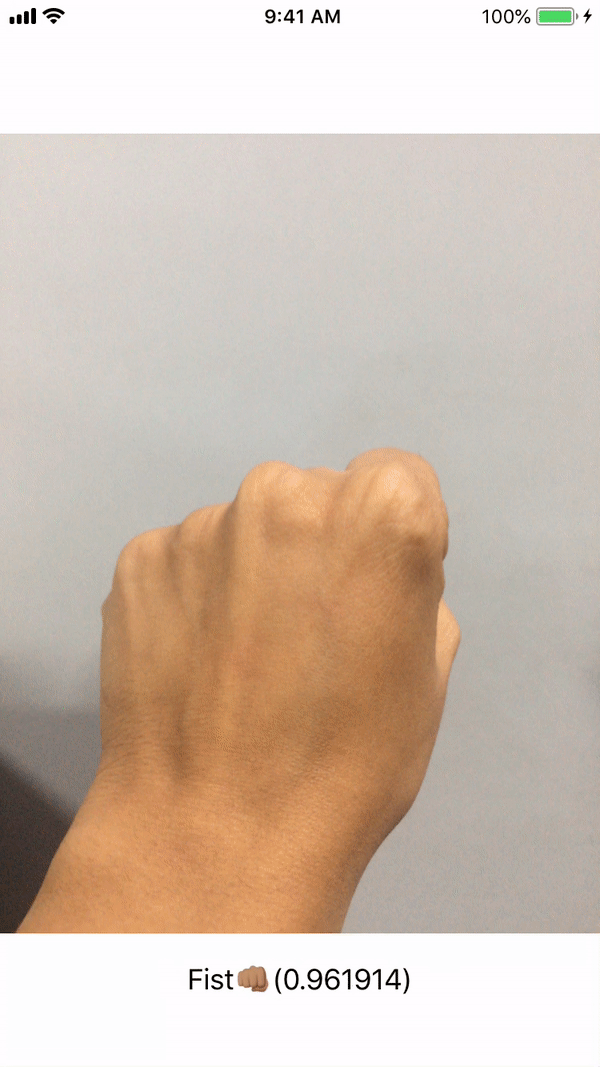Core ML is an interesting means to add a pre trained model to your app. But one thing that nagged me after trying my hands on Core ML was that how can I possibly train my own model and integrate in my apps using Core ML. Well, after doing some homework, a lot of light was dawned on me about the brilliant possibilities of achieving this. To be honest majorly all the ways require you to understand and know your math really well! While I was on this roller coaster ride, I came across Custom Vision. What a brilliant relief for developers who are looking at starting right away with training models and manifesting their machine learning ideas into the reality of mobile apps without diving too deep into the waters of machine learning.
Custom Vision
Microsoft’s Custom vision allows you to upload images with tags, train your model for classification of images in these tags and helps you export the trained model in formats preferred by you (we will be primarily focusing on Core ML format in this blog). Along with this, Custom Vision gives you a dashboard of the performance of your trained model gauging it on prediction and recall percentage. You can even test your trained model using their interface.
The free trial lets you create two projects and use them to train your models. We need to buy their services for anything beyond this. It’s a great start to try your hands at self training a machine learning model.
I will walk you through a basic hand sign detector, which recognises ROCK, PAPER, SCISSORS! By that I mean, it recognises a closed fist, an open palm and a victory sign. This can even be taken forward to build a sign language interpreter. So here goes! Bon Voyage!
Create a new Custom Vision Project
- Login to Custom Vision or sign up if you don’t have a microsoft account already.
- Once you sign in, add a new project and add a name and description to your project.
- The next thing you need to select is the project type. Our project type will be classification as we are building our own model. The other option is for a prebuilt object detection custom vision model.
- Choosing the classification type is use case dependant. It depends on the number of predictions that will be derived from one input image. For instance, whether you want to input a picture of a person and predict the gender, emotion and age of the person or just the gender of the person. If you wish your model to predict just one thing from one input image then choose – Multiclass (Single tag per image), else choose – Multilabel (Multiple tags per image). We will choose the former for this example.
- Finally the domain to be chosen is General (compact), which will gives a compact model suitable for mobile and gives an option to directly export the model as a Core ML model.

Figure 1: Create Project Dialogue Box on Custom Vision
Train your image classifier model
Once the project has been created, you would need a lot of pictures! And by lot, I mean lot! Here’s the deal, for each type of prediction you want your model to make, you need to train it with a bunch of images telling what is called what. It is like training a child to associate a word with anything that the child perceives, but just faster! 😛 For my model I trained it with around 60-70 images of – fist, open palm, victory sign and no hand. Below is list of things I did to train my model:
- Collect images! Now, diversity is the key in this activity. I collected images of all three signs in various lightings, various positions on the phone screen with different backgrounds and a lot of different hands. Thanks to all my awesome hand modelling volunteers (a.k.a family and friends)! You could do the same. This is the most fun part of the voyage.
Here are the snapshots of my memories from the voyage! More about them in the following points. - Each set of images needs to be tagged with a label that will be the output of your model after prediction. So we need to add these tags first. Add your tags with the ‘+’ button near ‘Tags’ label. I added four such tags – FistHand, FiveHand, NoHand, VictoryHand.
- Once you are done adding your tags, it is time to upload your images and tag them up! You need to click on Add Images option on the top of the screen. Upload all images belonging to one group together along with the tag for that group.
Quick Tip: Resize all your images to a smaller dimension so that the model size isn’t too big. Preview app will easily help you do it for all your images at one go. - All image sets have been added and tagged. Now all you need to do, to train your model is press a button! Click the ‘Train’ button on top. The wonderful machine learning engine of Custom Vision by Microsoft, trains a model for you using the images you feed it.
- After the engine finishes training your model, it opens the performance tab showing the performance of your model. Here you get to see the overall precision and recall percentage of your model along with precision and recall percentage for each tag. Based on how satisfied you are with your model’s performance, you can further improve it or use the same model. To re-train your model, add a few more variants for each tag to improve your model and hit the ‘Train’ button again.

Figure 2: Performance Tab on Custom Vision dashboard for trained model - You can test your model by clicking on the Quick Test button next to Train button on the top. Here you can upload new pictures and test your model for classification.
Using your trained model in your iOS app
You have two options at this point when you have a trained model you are satisfied with.
- You can either use an endpoint provided by Microsoft to hit it each time with an image and it will send back the prediction, both over the network. To view the endpoint details, go to the ‘Prediction’ tab and hit the ‘View Endpoint’ button. Here you will get all the details of the API endpoint. Works with both image url or actual image file.
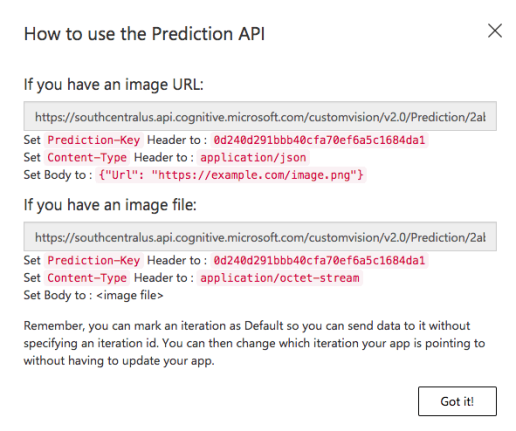 Figure 3: Prediction API for trained model
Figure 3: Prediction API for trained model - The other, faster and more secure path is the Core ML way. You can export your trained model as a Core ML model. This option is on the Performance Tab. Hit the Export button and then select the export type to be iOS – Core ML. Ta-Da! You have your .mlmodel file ready to be integrated in your iOS project.You will have something that does the following:

Figure 4: Input and ideal output of the HandSigns.mlmodel
Setup a live feed capture from phone camera
In this example, I have a live feed capture being sent to the Core ML model for giving out its prediction. So now we need to have a setup in place which will start the camera and start live capture and feed the buffer to our prediction model. This is a pretty straight forward bit of code that will surely look simple only if you understand what is happening.
- For this example, we take a Single Page Application project. It can be any other type depending on your requirements.
- Once in the project, let us build a method to configure our camera. This will be called in the viewDidLoad() method. We will do this with the help of AVCaptureSession and thus you will have to import AVKit.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersfunc configureCamera() { //Start capture session let captureSession = AVCaptureSession() captureSession.sessionPreset = .photo captureSession.startRunning() // Add input for capture guard let captureDevice = AVCaptureDevice.default(for: .video) else { return } guard let captureInput = try? AVCaptureDeviceInput(device: captureDevice) else { return } captureSession.addInput(captureInput) // Add preview layer to our view to display the open camera screen let previewLayer = AVCaptureVideoPreviewLayer(session: captureSession) view.layer.addSublayer(previewLayer) previewLayer.frame = view.frame // Add output of capture /* Here we set the sample buffer delegate to our viewcontroller whose callback will be on a queue named - videoQueue */ let dataOutput = AVCaptureVideoDataOutput() dataOutput.setSampleBufferDelegate(self, queue: DispatchQueue(label: "videoQueue")) captureSession.addOutput(dataOutput) } - As we are setting the video output buffer delegate to our viewcontroller, it must extend AVCaptureVideoDataOutputSampleBufferDelegate, in order to implement the didOutput sampleBuffer method to catch the sample buffers thrown out from the AVCaptureConnection.
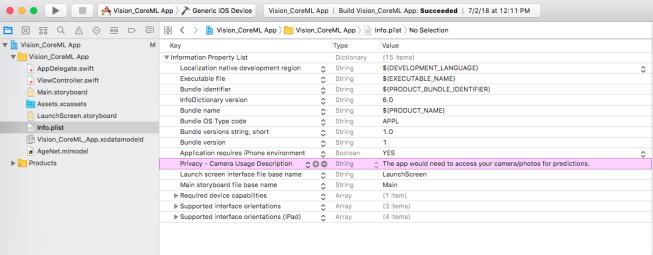
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersclass ViewController: UIViewController, AVCaptureVideoDataOutputSampleBufferDelegate { ... ... ... } - The last thing remaining for this setup is the permission for using camera to be listed in info.plist. Add Privacy Camera Usage Description and add a string value to this key. Something like – App needs camera for detection. Your setup is in place now! Go ahead and try to run it on a device and the app should open up the camera as it launches.

Figure 5: Info.list with Camera Usage Permission
Integrate your Core ML model in your iOS project
The real fun for which you have been taking all these efforts, begins now. As you must know, including coreml model in iOS project is as simple as dragging and dropping it in your project structure in XCode. Once you add your downloaded/exported coreml model, you can very well analyse it by clicking on it and checking the generated swift file for your model. Mine looks like this:

Figure 6: HandSign.mlmodel overview
The steps below will guide you through this:
- First things first, import the Vision library and import CoreML for this image classifier example. We will need it while initialising the model and using the core ML functionalities in our app.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersimport CoreML import Vision - Now we will make an enum for our prediction labels/tags.
- When our model outputs a result, we reduce it to a string type. You will need some UI component to display it. For that we will add a UILabel in our ViewController through the storyboard file and add the necessary constraints such that it is set at the bottom of the screen.
 Figure 7: UILabel for displaying prediction
Figure 7: UILabel for displaying prediction - Draw an outlet of the UILabel in your viewController. I have named it predicitonLabel.
- Once we have all of that in place, we can begin with the initialisation of our core ML model – HandSignsModel.mlmodel and extract the sample buffer input from AVCaptureConnection and feed it as an input to our hand sign detector model. We will then utilise the output of its prediction. To do so we will implement the didOutput sampleBuffer method of AVCaptureVideoDataOutputSampleBufferDelegate. Detailed step wise explanation of everything happening in this method is put up in the code comments inline. Seemed liked the best way to put it up.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters// MARK: - AVCaptureVideoDataOutputSampleBufferDelegate /* This delegate is fired periodically every time a new video frame is written. It is called on the dispatch queue specified while setting up the capture session. */ func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { /* Initialise CVPixelBuffer from sample buffer CVPixelBuffer is the input type we will feed our coremlmodel . */ guard let pixelBuffer: CVPixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } /* Initialise Core ML model We create a model container to be used with VNCoreMLRequest based on our HandSigns Core ML model. */ guard let handSignsModel = try? VNCoreMLModel(for: HandSigns().model) else { return } /* Create a Core ML Vision request The completion block will execute when the request finishes execution and fetches a response. */ let request = VNCoreMLRequest(model: handSignsModel) { (finishedRequest, err) in /* Dealing with the result of the Core ML Vision request The request's result is an array of VNClassificationObservation object which holds identifier - The prediction tag we had defined in our Custom Vision model - FiveHand, FistHand, VictoryHand, NoHand confidence - The confidence on the prediction made by the model on a scale of 0 to 1 */ guard let results = finishedRequest.results as? [VNClassificationObservation] else { return } /* Results array holds predictions iwth decreasing level of confidence. Thus we choose the first one with highest confidence. */ guard let firstResult = results.first else { return } var predictionString = "" /* Depending on the identifier we set the UILabel text with it's confidence. We update UI on the main queue. */ DispatchQueue.main.async { switch firstResult.identifier { case HandSign.fistHand.rawValue: predictionString = "Fist👊🏽" case HandSign.victoryHand.rawValue: predictionString = "Victory✌🏽" case HandSign.fiveHand.rawValue: predictionString = "High Five🖐🏽" case HandSign.noHand.rawValue: predictionString = "No Hand ❎" default: break } self.predictionLabel.text = predictionString + "(\(firstResult.confidence))" } } /* Perform the above request using Vision Image Request Handler We input our CVPixelbuffer to this handler along with the request declared above. */ try? VNImageRequestHandler(cvPixelBuffer: pixelBuffer, options: [:]).perform([request]) } }
Congratulations, you have built your very own machine learning model and integrated the same in an iOS app. You can find the entire project with the model and implementation here.
Here is a working demo of the app we have referred to through this tutorial: